When planning a study that will use statistical hypothesis tests to determine the significance of the results, one question researchers ask is, “how many subjects do I need?” There are three pieces of information needed to answer that question: 1) the alpha level, 2) the probability the test will detect an effect if an effect is actually there (statistical power), and 3) the desired size of the effect. Of these three, today we focus on effect sizes.
Effect Size
Effect size is a measure of practical significance of the result of a study. It is a way of quantifying the strength of a relationship or the magnitude of an observed effect. For example, when examining the effectiveness of an intervention using treatment and control groups, the p value from a statistical test indicates whether the difference in the scores of the treatment and control groups has statistical significance, while the effect size indicates the magnitude of the observed effect.
An effect size can be expressed in unstandardized (i.e., the original) units and/or in standardized units. A common standardized estimate of effect size for the difference between two groups is Cohen’s d; the mean difference between two groups divided by a pooled standard deviation (across groups).
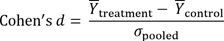
The appropriate effect size calculation is determined based on the chosen statistical analysis. Some selected effect sizes are presented in the table below.
Selected Effect Sizes

Determining Effect Size
Researchers who are planning studies must use an estimate of the effect size they expect to see in order to estimate the number of participants needed in the study. In some cases, the researcher has conducted a similar study in the past and can base the estimate of effect size on results from that study. The researcher could also review the literature for evidence of previously reported effect sizes and compute an average effect size. If prior studies cannot be found, researchers can choose a conservative effect size or a range of effect sizes based on the benchmarks proposed by Cohen (1988).
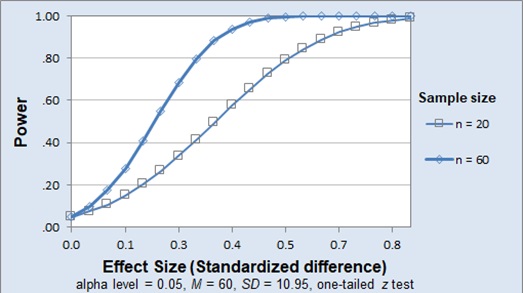
Once the effect size is selected, a power analysis can be conducted to determine the sample size required to achieve the desired level of power. As shown in the figure below, smaller effects require a larger sample size to achieve adequate power, holding all other study components constant. That is, the researcher will need more participants in order to detect a small effect.
The Essential Guide to Effect Sizes
For those who want a fuller understanding of this topic, we can recommend an excellent, jargon-free introduction to effect sizes: The Essential Guide to Effect Sizes: Statistical Power, Meta-analysis, and the Interpretation of Research Results by Paul D. Ellis (2010). We at the DAAC give this book five stars!
Reference:
Cohen, J. (1988). Statistical power analysis for the behavioral sciences. Hillsdale, NJ: Erlb